Drug design
Drug design is the process of how the active ingredients been manufacturing through finding new medications based on the knowledge of a biological target. Mostly, the drug is commonly an organic small molecule that inhibits or activates the function of a biomolecule such as a protein, resulting in a therapeutic benefit to the patient through reaching its target. Basically, drug design involves the design of small molecules that are complementary in shape and charge to the biomolecular target with which they interact and therefore will bind to it. Drug design frequently but not necessarily relies on computer modeling techniques.This type of modeling is often referred to as computer-aided drug design. Finally, drug design that relies on the knowledge of the three-dimensional structure of the biomolecular target is known as structure-based drug design.
The phrase "drug design" is to some extent a misnomer. What is really meant by drug design is ligand design (i.e., design of a small molecule that will bind tightly to its target). Although modeling techniques for prediction of binding affinity are reasonably successful, there are many other properties, such as bioavailability, metabolic half-life, lack of side effects, etc., that first must be optimized before a ligand can become a safe and efficacious drug. These other characteristics are often difficult to optimize using rational drug design techniques.
Background on Drug design:
Typically a drug target is a key molecule involved in a particular metabolic or signaling pathway that is specific to a disease condition or pathology or to the infectivity or survival of a microbial pathogen. Some approaches attempt to inhibit the functioning of the pathway in the diseased state by causing a key molecule to stop functioning. Drugs may be designed that bind to the active region and inhibit this key molecule. Another approach may be to enhance the normal pathway by promoting specific molecules in the normal pathways that may have been affected in the diseased state. In addition, these drugs should also be designed so as not to affect any other important "off-target" molecules or antitargets that may be similar in appearance to the target molecule, since drug interactions with off-target molecules may lead to undesirable side effects. Sequence homology is often used to identify such risks.Most commonly, drugs are organic small molecules produced through chemical synthesis, but biopolymer-based drugs (also known as biologics) produced through biological processes are becoming increasingly more common. In addition, mRNA-based gene silencing technologies may have therapeutic applications.
Types of Drug design:

Flow charts of two strategies of structure-based drug design
There are two major types of drug design. The first is referred to as ligand-based drug design and the second, structure-based drug design.
1) Ligand-based:
Ligand-based drug design (or indirect drug design) relies on knowledge of other molecules that bind to the biological target of interest. These other molecules may be used to derive a pharmacophore model that defines the minimum necessary structural characteristics a molecule must possess in order to bind to the target. In other words, a model of the biological target may be built based on the knowledge of what binds to it, and this model in turn may be used to design new molecular entities that interact with the target. Alternatively, a quantitative structure-activity relationship (QSAR), in which a correlation between calculated properties of molecules and their experimentally determined biological activity, may be derived. These QSAR relationships in turn may be used to predict the activity of new analogs.2) Structure-based:
Structure-based drug design (or direct drug design) relies on knowledge of the three dimensional structure of the biological target obtained through methods such as x-ray crystallography or NMR spectroscopy. If an experimental structure of a target is not available, it may be possible to create a homology model of the target based on the experimental structure of a related protein. Using the structure of the biological target, candidate drugs that are predicted to bind with high affinity and selectivity to the target may be designed using interactive graphics and the intuition of a medicinal chemist. Alternatively various automated computational procedures may be used to suggest new drug candidates.As experimental methods such as X-ray crystallography and NMR develop, the amount of information concerning 3D structures of biomolecular targets has increased dramatically. In parallel, information about the structural dynamics and electronic properties about ligands has also increased. This has encouraged the rapid development of the structure-based drug design. Current methods for structure-based drug design can be divided roughly into two categories. The first category is about “finding” ligands for a given receptor, which is usually referred as database searching. In this case, a large number of potential ligand molecules are screened to find those fitting the binding pocket of the receptor. This method is usually referred as ligand-based drug design. The key advantage of database searching is that it saves synthetic effort to obtain new lead compounds. Another category of structure-based drug design methods is about “building” ligands, which is usually referred as receptor-based drug design. In this case, ligand molecules are built up within the constraints of the binding pocket by assembling small pieces in a stepwise manner. These pieces can be either individual atoms or molecular fragments. The key advantage of such a method is that novel structures, not contained in any database, can be suggested.
- Active site identification:
Active site identification is the first step in this program. It analyzes the protein to find the binding pocket, derives key interaction sites within the binding pocket, and then prepares the necessary data for Ligand fragment link. The basic inputs for this step are the 3D structure of the protein and a pre-docked ligand in PDB format, as well as their atomic properties. Both ligand and protein atoms need to be classified and their atomic properties should be defined, basically, into four atomic types:- hydrophobic atom: All carbons in hydrocarbon chains or in aromatic groups.
- H-bond donor: Oxygen and nitrogen atoms bonded to hydrogen atom(s).
- H-bond acceptor: Oxygen and sp2 or sp hybridized nitrogen atoms with lone electron pair(s).
- Polar atom: Oxygen and nitrogen atoms that are neither H-bond donor nor H-bond acceptor, sulfur, phosphorus, halogen, metal, and carbon atoms bonded to hetero-atom(s).
The space inside the ligand binding region would be studied with virtual probe atoms of the four types above so the chemical environment of all spots in the ligand binding region can be known. Hence we are clear what kind of chemical fragments can be put into their corresponding spots in the ligand binding region of the receptor.
- Ligand fragment link:

Flow chart for structure-based drug design
When we want to plant “seeds” into different regions defined by the previous section, we need a fragments database to choose fragments from. The term “fragment” is used here to describe the building blocks used in the construction process. The rationale of this algorithm lies in the fact that organic structures can be decomposed into basic chemical fragments. Although the diversity of organic structures is infinite, the number of basic fragments is rather limited.
Before the first fragment, i.e. the seed, is put into the binding pocket, and other fragments can be added one by one, it is useful to identify potential problems. First, the possibility for the fragment combinations is huge. A small perturbation of the previous fragment conformation would cause great difference in the following construction process. At the same time, in order to find the lowest binding energy on the Potential energy surface (PES) between planted fragments and receptor pocket, the scoring function calculation would be done for every step of conformation change of the fragments derived from every type of possible fragments combination. Since this requires a large amount of computation, using different tricks may use less computing power and let the program work more efficiently.
When a ligand is inserted into the pocket site of a receptor, groups on the ligand that bind tightly with the receptor should have the highest priority in finding their lowest-energy conformation. This allows us to put several seeds into the program at the same time and optimize the conformation of those seeds that form significant interactions with the receptor, and then connect those seeds into a continuous ligand in a manner that make the rest of the ligand have the lowest energy. The pre-placed seeds ensure high binding affinity and their optimal conformation determines the manner in which the ligand will be built, thus determining the overall structure of the final ligand. This strategy efficiently reduces the calculation burden for fragment construction. On the other hand, it reduces the possibility of the combination of fragments, which reduces the number of possible ligands that can be derived from the program. The two strategies above are widely used in most structure-based drug design programs. They are described as “Grow” and “Link”. The two strategies are always combined in order to make the construction result more reliable.
- Scoring method:
Structure-based drug design attempts to use the structure of proteins as a basis for designing new ligands by applying accepted principles of molecular recognition. The basic assumption underlying structure-based drug design is that a good ligand molecule should bind tightly to its target. Thus, one of the most important principles for designing or obtaining potential new ligands is to predict the binding affinity of a certain ligand to its target and use it as a criterion for selection.One early method was developed by Böhm to develop a general-purposed empirical scoring function in order to describe the binding energy. The following “Master Equation” was derived:
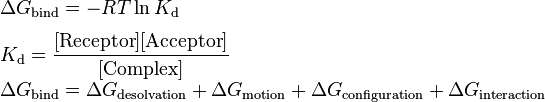
where:
- desolvation – enthalpic penalty for removing the ligand from solvent
- motion – entropic penalty for reducing the degrees of freedom when a ligand binds to its receptor
- configuration – conformational strain energy required to put the ligand in its "active" conformation
- interaction – enthalpic gain for "resolvating" the ligand with its receptor
The basic idea is that the overall binding free energy can be decomposed into independent components that are known to be important for the binding process. Each component reflects a certain kind of free energy alteration during the binding process between a ligand and its target receptor. The Master Equation is the linear combination of these components. According to Gibbs free energy equation, the relation between dissociation equilibrium constant, Kd, and the components of free energy was built.
Various computational methods are used to estimate each of the components of the master equation. For example, the change in polar surface area upon ligand binding can be used to estimate the desolvation energy. The number of rotatable bonds frozen upon ligand binding is proportional to the motion term. The configurational or strain energy can be estimated using molecular mechanics calculations. Finally the interaction energy can be estimated using methods such as the change in non polar surface, statistically derived potentials of mean force, the number of hydrogen bonds formed, etc. In practice, the components of the master equation are fit to experimental data using multiple linear regression. This can be done with a diverse training set including many types of ligands and receptors to produce a less accurate but more general "global" model or a more restricted set of ligands and receptors to produce a more accurate but less general "local" model.
Rational drug discovery:
In contrast to traditional methods of drug discovery, which rely on trial-and-error testing of chemical substances on cultured cells or animals, and matching the apparent effects to treatments, rational drug design begins with a hypothesis that modulation of a specific biological target may have therapeutic value. In order for a biomolecule to be selected as a drug target, two essential pieces of information are required. The first is evidence that modulation of the target will have therapeutic value. This knowledge may come from, for example, disease linkage studies that show an association between mutations in the biological target and certain disease states. The second is that the target is "drugable". This means that it is capable of binding to a small molecule and that its activity can be modulated by the small molecule.Once a suitable target has been identified, the target is normally cloned and expressed. The expressed target is then used to establish a screening assay. In addition, the three-dimensional structure of the target may be determined.
The search for small molecules that bind to the target is begun by screening libraries of potential drug compounds. This may be done by using the screening assay (a "wet screen"). In addition, if the structure of the target is available, a virtual screen may be performed of candidate drugs. Ideally the candidate drug compounds should be "drug-like", that is they should possess properties that are predicted to lead to oral bioavailability, adequate chemical and metabolic stability, and minimal toxic effects. Several methods are available to estimate druglikeness such as Lipinski's Rule of Five and a range of scoring methods such as Lipophilic efficiency. Several methods for predicting drug metabolism have been proposed in the scientific literature, and a recent example is SPORCalc. Due to the complexity of the drug design process, two terms of interest are still serendipity and bounded rationality. Those challenges are caused by the large chemical space describing potential new drugs without side-effects.
Computer-aided drug design:
Computer-aided drug design uses computational chemistry to discover, enhance, or study drugs and related biologically active molecules. The most fundamental goal is to predict whether a given molecule will bind to a target and if so how strongly. Molecular mechanics or molecular dynamics are most often used to predict the conformation of the small molecule and to model conformational changes in the biological target that may occur when the small molecule binds to it. Semi-empirical, ab initio quantum chemistry methods, or density functional theory are often used to provide optimized parameters for the molecular mechanics calculations and also provide an estimate of the electronic properties (electrostatic potential, polarizability, etc.) of the drug candidate that will influence binding affinity.Molecular mechanics methods may also be used to provide semi-quantitative prediction of the binding affinity. Also, knowledge-based scoring function may be used to provide binding affinity estimates. These methods use linear regression, machine learning, neural nets or other statistical techniques to derive predictive binding affinity equations by fitting experimental affinities to computationally derived interaction energies between the small molecule and the target.
Ideally the computational method should be able to predict affinity before a compound is synthesized and hence in theory only one compound needs to be synthesized. The reality however is that present computational methods are imperfect and provide at best only qualitatively accurate estimates of affinity. Therefore in practice it still takes several iterations of design, synthesis, and testing before an optimal molecule is discovered. On the other hand, computational methods have accelerated discovery by reducing the number of iterations required and in addition have often provided more novel small molecule structures.
Drug design with the help of computers may be used at any of the following stages of drug discovery:
- hit identification using virtual screening (structure- or ligand-based design)
- hit-to-lead optimization of affinity and selectivity (structure-based design, QSAR, etc.)
- lead optimization optimization of other pharmaceutical properties while maintaining affinity

Flowchart of a Usual Clustering Analysis for Structure-Based Drug Design
In order to overcome the insufficient prediction of binding affinity calculated by recent scoring functions, the protein-ligand interaction and compound 3D structure information are used to analysis. For structure-based drug design, several post-screening analysis focusing on protein-ligand interaction has been developed for improving enrichment and effectively mining potential candidates:
- Consensus scoring
- Selecting candidates by voting of multiple scoring functions
- May lose the relationship between protein-ligand structural information and scoring criterion
- Geometric analysis
- Comparing protein-ligand interactions by visually inspecting individual structures
- Becoming intractable when the number of complexes to be analyzed increasing
- Cluster analysis
- Represent and cluster candidates according to protein-ligand 3D information
- Needs meaningful representation of protein-ligand interactions.
Examples:
A particular example of rational drug design involves the use of three-dimensional information about biomolecules obtained from such techniques as X-ray crystallography and NMR spectroscopy. Computer-aided drug design in particular becomes much more tractable when there is a high-resolution structure of a target protein bound to a potent ligand. This approach to drug discovery is sometimes referred to as structure-based drug design. The first unequivocal example of the application of structure-based drug design leading to an approved drug is the carbonic anhydrase inhibitor dorzolamide, which was approved in 1995.Another important case study in rational drug design is imatinib, a tyrosine kinase inhibitor designed specifically for the bcr-abl fusion protein that is characteristic for Philadelphia chromosome-positive leukemias (chronic myelogenous leukemia and occasionally acute lymphocytic leukemia). Imatinib is substantially different from previous drugs for cancer, as most agents of chemotherapy simply target rapidly dividing cells, not differentiating between cancer cells and other tissues.
Additional examples include:
- Many of the atypical antipsychotics
- Cimetidine, the prototypical H2-receptor antagonist from which the later members of the class were developed:
- Selective COX-2 inhibitor NSAIDs
- Dorzolamide, a carbonic anhydrase inhibitor used to treat glaucoma
- Enfuvirtide, a peptide HIV entry inhibitor
- Nonbenzodiazepines like zolpidem and zopiclone
- Probenecid
- SSRIs (selective serotonin reuptake inhibitors), a class of antidepressants
- Zanamivir, an antiviral drug
- Isentress, HIV Integrase inhibitor
- 5-HT3 antagonists
- Acetylcholine receptor agonists
- Angiotensin receptor blockers
- Bcr-Abl tyrosine kinase inhibitors
- Cannabinoid receptor antagonists
- CCR5 receptor antagonists
- Cyclooxygenase 2 inhibitors
- Dipeptidyl peptidase-4 inhibitors
- HIV protease inhibitors
- NK1 receptor antagonists
- Non-nucleoside reverse transcriptase inhibitors
- Proton pump inibitors
- Triptans
- TRPV1 antagonists
- Renin inhibitors
- c-Met inhibitors
REFERENCE:
https://en.wikipedia.org/wiki/Drug_design







0 comments:
Post a Comment